我有一组由10个特征组成的观测数据,每个特征都是区间(0,2)内的实数。假设我想训练一个简单的神经网络来分类这些特征的平均值是否高于或低于1.0。
除非我遗漏了什么,否则应该使用一个两层网络,每层各有一个神经元就足够了。第一层的激活函数是线性的(即没有激活函数),输出层的激活函数是Sigmoid。一个具有这种架构且能够工作的神经网络示例是:第一层计算平均值(即所有权重=0.1,偏置=0),第二层评估该平均值是否高于或低于1.0(即权重=1.0,偏置=-1.0)。
当我使用TensorFlow实现这个(见下方代码)时,我显然很快就得到了很高的准确率,但从未达到100%的准确率… 我希望能得到一些帮助,以概念上理解为什么会这样。我不明白为什么反向传播算法无法达到一组最优权重(可能是与我使用的损失函数有关,该函数有局部最小值?)。另外,我想知道如果我使用不同的激活函数和/或损失函数,是否可以达到100%的准确率。
import numpy as npimport tensorflow as tfimport matplotlib.pyplot as plt X = [np.random.random(10)*2.0 for _ in range(10000)]X = np.array(X)y = X.mean(axis=1) >= 1.0y = y.astype('int')train_ratio = 0.8train_len = int(X.shape[0]*0.8)X_train, X_test = X[:train_len,:], X[train_len:,:]y_train, y_test = y[:train_len], y[train_len:]def create_classifier(lr = 0.001): classifier = tf.keras.Sequential() classifier.add(tf.keras.layers.Dense(units=1)) classifier.add(tf.keras.layers.Dense(units=1, activation='sigmoid'))#, input_shape=input_shape)) optimizer = tf.keras.optimizers.Adam(learning_rate=lr) metrics=[tf.keras.metrics.BinaryAccuracy()], classifier.compile(optimizer=optimizer, loss=tf.keras.losses.BinaryCrossentropy(from_logits=False), metrics=metrics) return classifierclassifier = create_classifier(lr = 0.1)history = classifier.fit(X_train, y_train, batch_size=1000, validation_split=0.1, epochs=2000)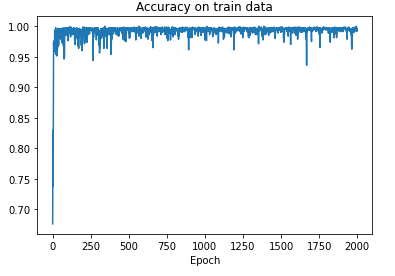
回答:
忽略神经网络对于这个问题来说是一个奇怪的方法这一事实,回答你的具体问题 – 看起来你的学习率可能太高了,这可能解释了在最佳点周围的波动。