MuZero是一种深度强化学习技术,刚刚发布,我正在尝试通过查看其伪代码和Medium上的这个有用教程来实现它。
然而,关于伪代码中训练过程中奖励的处理方式有一点让我感到困惑,如果有人能验证我是否正确地阅读了代码,并且如果我是对的,解释为什么这种训练算法有效,那就太好了。
这是训练函数(来自伪代码):
def update_weights(optimizer: tf.train.Optimizer, network: Network, batch, weight_decay: float): loss = 0 for image, actions, targets in batch: # Initial step, from the real observation. value, reward, policy_logits, hidden_state = network.initial_inference( image) predictions = [(1.0, value, reward, policy_logits)] # Recurrent steps, from action and previous hidden state. for action in actions: value, reward, policy_logits, hidden_state = network.recurrent_inference( hidden_state, action) predictions.append((1.0 / len(actions), value, reward, policy_logits)) hidden_state = tf.scale_gradient(hidden_state, 0.5) for prediction, target in zip(predictions, targets): gradient_scale, value, reward, policy_logits = prediction target_value, target_reward, target_policy = target l = ( scalar_loss(value, target_value) + scalar_loss(reward, target_reward) + tf.nn.softmax_cross_entropy_with_logits( logits=policy_logits, labels=target_policy)) loss += tf.scale_gradient(l, gradient_scale) for weights in network.get_weights(): loss += weight_decay * tf.nn.l2_loss(weights) optimizer.minimize(loss)我特别关注的是损失函数中的reward。请注意,损失函数中的所有值都来自predictions。第一个添加到predictions中的reward来自network.initial_inference函数。此后,还有len(actions)个reward被添加到predictions中,这些都来自network.recurrent_inference函数。
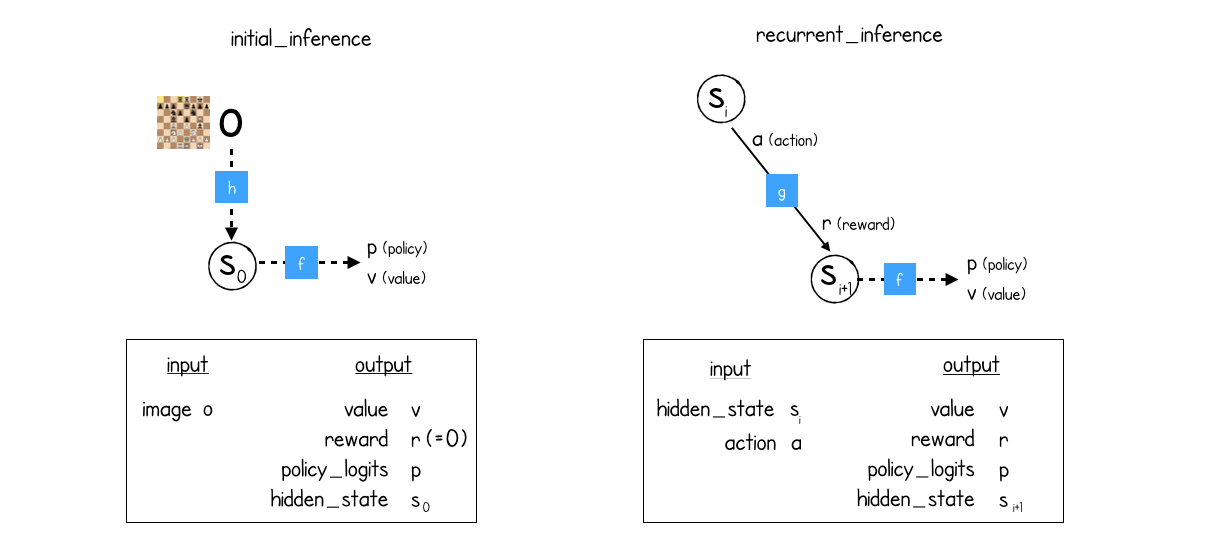
根据教程,initial_inference和recurrent_inference函数由以下三个不同函数构建而成:
- 预测 输入:游戏的内部状态。输出:策略、值(预测的最佳未来奖励总和)
- 动态 输入:游戏的内部状态、动作。输出:执行该动作后的奖励、游戏的新内部状态。
- 表示 输入:游戏的外部状态。输出:游戏的内部状态
initial_inference函数接收外部游戏状态,使用representation函数将其转换为内部状态,然后在该内部游戏状态上使用prediction函数。它输出内部状态、策略和值。
recurrent_inference函数接收内部游戏状态和一个动作。它使用dynamics函数从旧的游戏状态和动作中获得新的内部游戏状态和奖励。然后,它对新内部游戏状态应用prediction函数,以获得新内部状态的策略和值。因此,最终输出是一个新的内部状态、一个奖励、一个策略和一个值。
然而,在伪代码中,initial_inference函数也返回了一个奖励。
我的主要问题是:这个奖励代表什么?
在教程中,他们只是隐式地假设initial_inference函数的奖励为0。(参见教程中的这张图片。)那么,是这样吗?实际上没有奖励,所以initial_inference总是返回奖励的0吗?
{kind=link}
让我们假设这是真的。
在这种假设下,predictions列表中的第一个奖励将是initial_inference函数为奖励返回的0。然后,在损失函数中,这个0将与target列表的第一个元素进行比较。
target是如何创建的:
def make_target(self, state_index: int, num_unroll_steps: int, td_steps: int, to_play: Player): # The value target is the discounted root value of the search tree N steps # into the future, plus the discounted sum of all rewards until then. targets = [] for current_index in range(state_index, state_index + num_unroll_steps + 1): bootstrap_index = current_index + td_steps if bootstrap_index < len(self.root_values): value = self.root_values[bootstrap_index] * self.discount**td_steps else: value = 0 for i, reward in enumerate(self.rewards[current_index:bootstrap_index]): value += reward * self.discount**i # pytype: disable=unsupported-operands if current_index < len(self.root_values): targets.append((value, self.rewards[current_index], self.child_visits[current_index])) else: # States past the end of games are treated as absorbing states. targets.append((0, 0, [])) return targets此函数返回的targets成为update_weights函数中的target列表。因此,targets中的第一个值是self.rewards[current_index]。self.rewards是玩游戏时接收的所有奖励的列表。唯一编辑它的时间是在这个apply函数中:
def apply(self, action: Action): reward = self.environment.step(action) self.rewards.append(reward) self.history.append(action)apply函数仅在此处调用:
# Each game is produced by starting at the initial board position, then# repeatedly executing a Monte Carlo Tree Search to generate moves until the end# of the game is reached.def play_game(config: MuZeroConfig, network: Network) -> Game: game = config.new_game() while not game.terminal() and len(game.history) < config.max_moves: # At the root of the search tree we use the representation function to # obtain a hidden state given the current observation. root = Node(0) current_observation = game.make_image(-1) expand_node(root, game.to_play(), game.legal_actions(), network.initial_inference(current_observation)) add_exploration_noise(config, root) # We then run a Monte Carlo Tree Search using only action sequences and the # model learned by the network. run_mcts(config, root, game.action_history(), network) action = select_action(config, len(game.history), root, network) game.apply(action) game.store_search_statistics(root) return game对我来说,看起来是每次采取动作时都会生成一个奖励。因此,self.rewards列表中的第一个奖励应该是游戏中采取第一个动作的奖励。
如果current_index = 0在self.rewards[current_index]中,问题就变得清晰了。在这种情况下,predictions列表中的第一个奖励将始终为0。然而,targets列表将包含完成第一个动作的奖励。
因此,对我来说,奖励似乎是错位的。
如果我们继续,predictions列表中的第二个奖励将是recurrent_inference为完成第一个动作的奖励。然而,targets列表中的第二个奖励将是游戏中存储的完成第二个动作的奖励。
总的来说,我有三个相互关联的问题:
initial_inference中的奖励代表什么?(它是什么?)- 如果它是0,并且它应该代表一个奖励,那么
predictions和targets之间的奖励是否错位?(即,predictions中的第二个奖励是否应该与targets中的第一个奖励匹配?) - 如果它们错位了,网络是否仍然能正确训练和工作?
(值得注意的另一个好奇之处是,尽管存在这种错位(假设存在错位),predictions和targets的长度确实是相同的。目标长度由make_target函数中的行for current_index in range(state_index, state_index + num_unroll_steps + 1)定义。我们还计算出predictions的长度为len(actions) + 1。而len(actions)由sample_batch函数中的g.history[i:i + num_unroll_steps]定义(参见伪代码)。因此,两个列表的长度相同。)
这是怎么回事?
回答:
作者在此。
initial_inference中的奖励代表什么?
初始推断“预测”最后观察到的奖励。这实际上不用于任何事情,但使我们的代码更简单:预测头可以简单地始终预测紧接着的前一个奖励。对于动态网络,这将是应用于动态网络输入的动作后观察到的奖励。
在游戏开始时没有最后观察到的奖励,所以我们将其设置为0。
伪代码中的奖励目标计算确实是错位的;我刚刚上传了arXiv的新版本。
原来的代码是这样的:
if current_index < len(self.root_values): targets.append((value, self.rewards[current_index], self.child_visits[current_index])) else: # States past the end of games are treated as absorbing states. targets.append((0, 0, []))应该改为:
# For simplicity the network always predicts the most recently received # reward, even for the initial representation network where we already # know this reward. if current_index > 0 and current_index <= len(self.rewards): last_reward = self.rewards[current_index - 1] else: last_reward = 0 if current_index < len(self.root_values): targets.append((value, last_reward, self.child_visits[current_index])) else: # States past the end of games are treated as absorbing states. targets.append((0, last_reward, []))希望这对你有帮助!