我有一个包含10个变量的数据集:
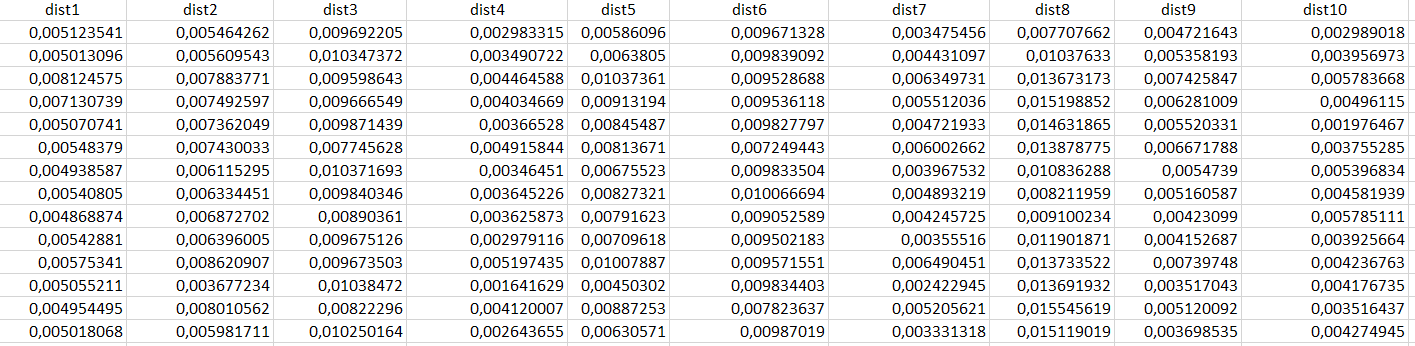
我想用这个多维数据集来识别聚类,所以我尝试了以下代码的k-means聚类算法:
clustering_kmeans = KMeans(n_clusters=2, precompute_distances="auto", n_jobs=-1)data['clusters'] = clustering_kmeans.fit_predict(data)为了绘制结果,我使用PCA进行了降维处理:
reduced_data = PCA(n_components=2).fit_transform(data)results = pd.DataFrame(reduced_data,columns=['pca1','pca2'])sns.scatterplot(x="pca1", y="pca2", hue=kmeans['clusters'], data=results)plt.title('K-means Clustering with 2 dimensions')plt.show()最后我得到了以下结果:
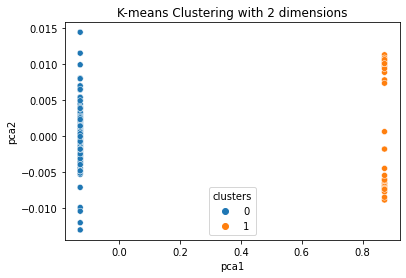
因此我有以下几个问题:
-
然而,这个PCA图看起来很奇怪,将整个数据集分到了图的两个角落。这是否正确,或者是我代码写错了?
-
还有没有其他用于聚类多维数据的算法?我查看了这个,但我找不到适合聚类多维数据的算法… 例如,如何在我的数据集上用Python实现Ward层次聚类?
-
为什么我应该使用PCA进行降维处理?我也可以使用t-SNE吗?哪个更好?
回答:
-
问题在于您对数据框进行了PCA拟合,但数据框包含了聚类。’cluster’列可能包含数据集中大部分的变化,因此第一个主成分的信息将与
data['cluster']列重合。尝试仅对距离列进行PCA拟合:data_reduced = PCA(n_componnts=2).fit_transform(data[['dist1', 'dist2',..., dist10']] -
您可以使用sklearn来拟合层次聚类:
sklearn.cluster.AgglomerativeClustering()`您可以使用不同的距离度量和链接方式,如’ward’
-
t-SNE用于可视化多变量数据,其技术目标不是聚类