我在使用sklearn和SVC对iris数据集进行sigmoid核的SVM测试时,其性能极差,准确率仅为25%。我使用了与https://towardsdatascience.com/a-guide-to-svm-parameter-tuning-8bfe6b8a452c(sigmoid部分)完全相同的代码,并对特征进行了归一化处理,这应该会显著提高性能。然而,我无法重现他的结果,准确率仅提高到33%。
使用其他核函数(例如线性核)可以得到良好的结果(准确率为82%)。SVC(kernel = ‘sigmoid’)函数内部是否存在问题?
重现问题的Python代码:
##sigmoid iris examplefrom sklearn import datasets iris = datasets.load_iris()from sklearn.svm import SVC sepal_length = iris.data[:,0] sepal_width = iris.data[:,1]#assessing performance of sigmoid SVMclf = SVC(kernel='sigmoid') clf.fit(np.c_[sepal_length, sepal_width], iris.target) pr=clf.predict(np.c_[sepal_length, sepal_width])pd.DataFrame(classification_report(iris.target, pr, output_dict=True))from sklearn.metrics.pairwise import sigmoid_kernel sigmoid_kernel(np.c_[sepal_length, sepal_width]) #normalizing featuresfrom sklearn.preprocessing import normalize sepal_length_norm = normalize(sepal_length.reshape(1, -1))[0] sepal_width_norm = normalize(sepal_width.reshape(1, -1))[0] clf.fit(np.c_[sepal_length_norm, sepal_width_norm], iris.target) sigmoid_kernel(np.c_[sepal_length_norm, sepal_width_norm]) #assessing perfomance of sigmoid SVM with normalized featurespr_norm=clf.predict(np.c_[sepal_length_norm, sepal_width_norm])pd.DataFrame(classification_report(iris.target, pr_norm, output_dict=True))回答:
我明白了。在sklearn的0.22版本之前的发布中,传递给SVC的默认gamma参数是”auto”,在后续版本中改为”scale”。文章的作者似乎使用了早期版本,因此隐式传递了gamma="auto"(他提到“gamma的当前默认设置是‘auto’”)。所以,如果你使用的是sklearn的最新版本(0.23.2),在实例化SVC时,你需要明确传递gamma='auto':
clf = SVC(kernel='sigmoid',gamma='auto') #normalizing featuressepal_length_norm = normalize(sepal_length.reshape(1, -1))[0] sepal_width_norm = normalize(sepal_width.reshape(1, -1))[0] clf.fit(np.c_[sepal_length_norm, sepal_width_norm], iris.target)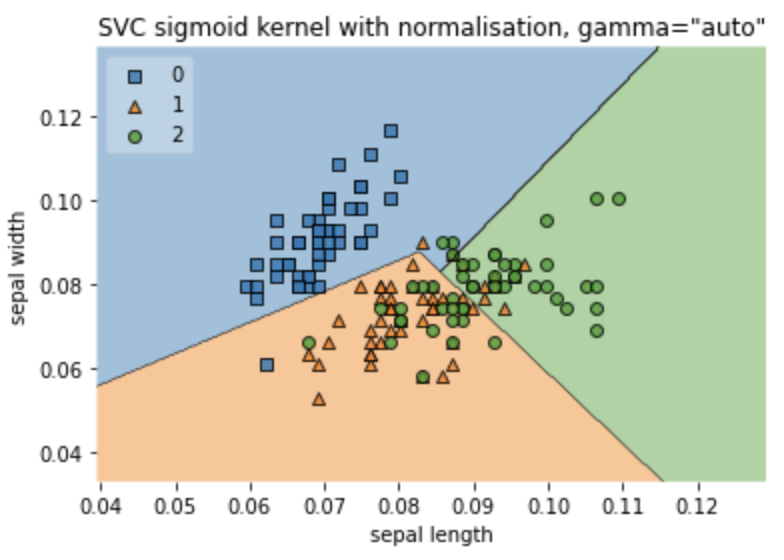
现在,当你打印分类报告时:
pr_norm=clf.predict(np.c_[sepal_length_norm, sepal_width_norm])print(pd.DataFrame(classification_report(iris.target, pr_norm, output_dict=True)))# 0 1 2 accuracy macro avg weighted avg# precision 0.907407 0.650000 0.750000 0.766667 0.769136 0.769136# recall 0.980000 0.780000 0.540000 0.766667 0.766667 0.766667# f1-score 0.942308 0.709091 0.627907 0.766667 0.759769 0.759769# support 50.000000 50.000000 50.000000 0.766667 150.000000 150.000000你之前看到的33%准确率可以解释为默认的gamma是”scale”,这导致所有预测都集中在决策平面上的一个区域,而目标被分为三部分,因此最大准确率为33.3%:
clf = SVC(kernel='sigmoid') #normalizing featuressepal_length_norm = normalize(sepal_length.reshape(1, -1))[0] sepal_width_norm = normalize(sepal_width.reshape(1, -1))[0] clf.fit(np.c_[sepal_length_norm, sepal_width_norm], iris.target) X = np.c_[sepal_length_norm, sepal_width_norm]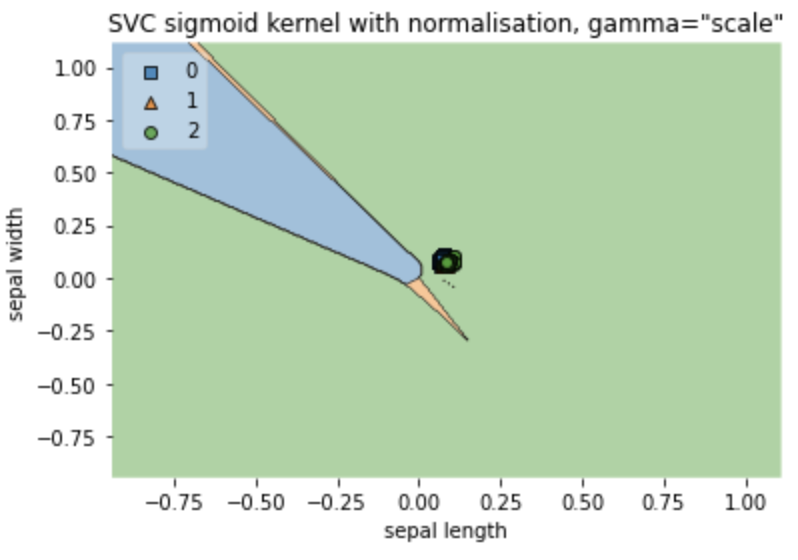
pr_norm=clf.predict(np.c_[sepal_length_norm, sepal_width_norm])print(pd.DataFrame(classification_report(iris.target, pr_norm, output_dict=True)))# 0 1 2 accuracy macro avg weighted avg# precision 0.0 0.0 0.333333 0.333333 0.111111 0.111111# recall 0.0 0.0 1.000000 0.333333 0.333333 0.333333# f1-score 0.0 0.0 0.500000 0.333333 0.166667 0.166667# support 50.0 50.0 50.000000 0.333333 150.000000 150.000000